Friendli Engine
About Friendli Engine
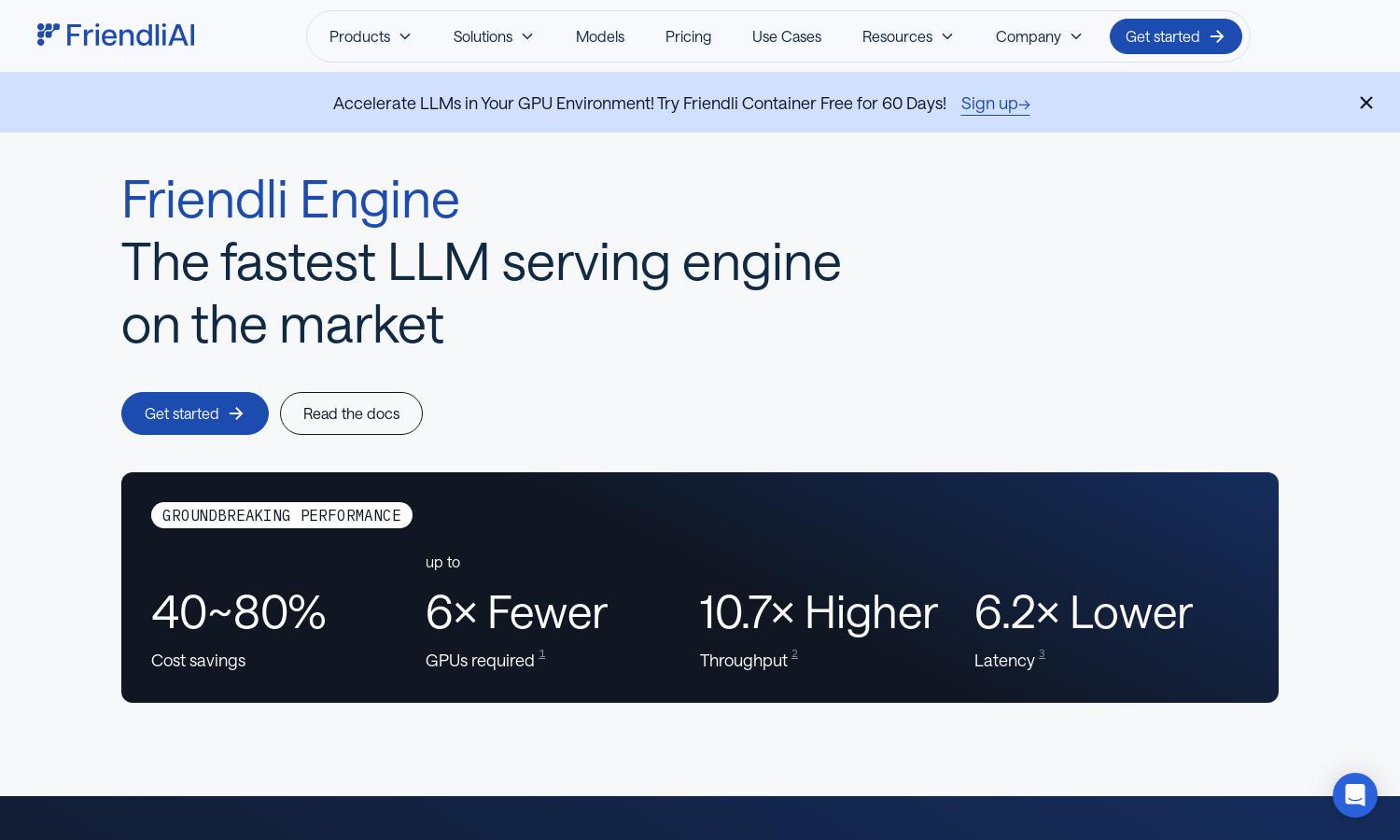
Friendli Engine streamlines LLM inference, targeting developers and businesses needing efficient AI model deployment. Using advanced technologies like iteration batching and speculative decoding, it significantly enhances speed and reduces costs. Friendli Engine enables users to fine-tune and deploy models effectively, solving performance bottlenecks in AI applications.
Friendli Engine offers flexible pricing plans catering to various user needs, providing free trials for initial exploration. Users can choose plans that balance performance and cost, with substantial incentives for upgrading, ensuring access to cutting-edge features and improved throughput as they scale their AI implementations.
Friendli Engine features a user-friendly interface designed for seamless navigation and efficient model management. Its intuitive layout facilitates rapid onboarding and effortless interaction with generative AI models. Unique elements, like integrated performance metrics, enhance the browsing experience, making it easy for users to optimize their AI solutions.
How Friendli Engine works
Users start by signing up on Friendli Engine, quickly gaining access to advanced tools for LLM inference. After onboarding, they can deploy models via Dedicated Endpoints, Containers, or Serverless Endpoints. The step-by-step tutorials guide users through optimizing their AI models, leveraging powerful features like iteration batching and caching for maximum efficiency and speed.
Key Features for Friendli Engine
High-Performance LLM Inference
Friendli Engine's high-performance LLM inference optimizes generative AI model deployment, offering unmatched speed and efficiency. By supporting multiple models on fewer GPUs, it ensures users can achieve significant cost reductions while maintaining exceptional performance levels, making it a top choice in the market.
Multi-LoRA Serving Capability
Friendli Engine's unique multi-LoRA serving capability allows users to run several LoRA models on a single GPU. This innovative feature enhances model customization and accessibility, enabling users to efficiently manage diverse generative AI tasks without the need for extensive hardware setups.
Speculative Decoding Feature
The speculative decoding feature of Friendli Engine accelerates LLM inference by making intelligent predictions about future tokens while generating the current token. This innovative approach significantly reduces inference time without compromising output accuracy, marking a major advancement in generative AI performance.
You may also like: