Agenta
Agenta is an open-source platform that streamlines LLM development, enabling teams to collaborate and build reliable.
Visit
About Agenta
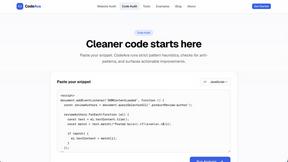
Agenta is an open-source LLMOps platform designed as a comprehensive solution for teams developing large language model (LLM) applications. It addresses the chaos often associated with LLM development by centralizing disparate workflows into a structured and collaborative environment. With Agenta, developers, product managers, and domain experts can come together, enhancing communication and efficiency. The platform provides integrated tools for prompt management, evaluation, and observability, transforming the LLM development process into a systematic engineering discipline. By eliminating guesswork and silos, Agenta helps teams ship reliable AI features with confidence. If your organization has been struggling with the unpredictability of LLMs and disjointed workflows, Agenta offers the infrastructure needed to streamline development and foster collaboration.
Features of Agenta
Centralized Prompt Management
Agenta allows you to centralize all your prompts, evaluations, and traces in one platform. This eliminates the confusion of scattered files and improves accessibility for all team members, ensuring everyone is on the same page.
Automated Evaluations
With Agenta, you can create a systematic process to run experiments, track results, and validate every change made to your LLMs. This feature replaces guesswork with evidence by providing automated evaluations that help you understand what changes impact performance.
Unified Playground
The platform includes a unified playground where you can compare prompts and models side-by-side. This feature is invaluable for identifying the best-performing prompts and models, allowing for quick iterations and improvements.
Real-time Observability
Agenta provides tools for monitoring production systems and tracing every request. This feature allows you to gather user feedback efficiently, debug your AI systems, and detect regressions, ensuring a smoother user experience.
Use Cases of Agenta
Collaborative Prompt Development
In teams where multiple stakeholders are involved, Agenta facilitates collaborative prompt development by providing a shared workspace. This enables product managers, developers, and domain experts to work together effectively, improving the quality of prompts.
Rigorous Evaluation Processes
Agenta is ideal for organizations that require rigorous evaluation processes. By automating evaluations and integrating domain expert feedback, teams can ensure that their LLMs meet high standards before deployment, reducing the risk of errors in production.
Debugging and Troubleshooting
When issues arise in production, Agenta’s observability tools help teams trace failures to their source. This capability allows for more efficient debugging, as you can pinpoint problems quickly and take corrective action.
Rapid Iteration of LLMs
For teams focused on rapid iteration, Agenta provides the tools necessary to test and compare various prompts and models in real-time. This accelerates the development cycle, allowing businesses to bring reliable AI features to market faster.
Frequently Asked Questions
What makes Agenta different from other LLM tools?
Agenta stands out by providing a comprehensive, open-source platform that centralizes workflows, enhances collaboration, and applies LLMOps best practices. This structured approach minimizes guesswork and maximizes reliability.
Is Agenta suitable for small teams?
Absolutely. Agenta is designed to cater to teams of all sizes, from small startups to large enterprises. Its collaborative features and centralized management make it particularly useful for teams looking to streamline their LLM development processes.
Can Agenta integrate with existing tools?
Yes, Agenta seamlessly integrates with various frameworks and models, including LangChain and OpenAI. This flexibility allows teams to leverage their existing tech stack while benefiting from Agenta's powerful features.
Is there a community for Agenta users?
Yes, Agenta boasts an active community where users can ask questions, share ideas, and collaborate on projects. Joining the community can help you get the most out of Agenta and connect with other AI builders.
Explore more in this category:
Similar to Agenta
JavaScript Tools
Formatters for JSON, HTML, CSS, XML, and Markdown
online audio test
This comprehensive suite offers a collection of free, browser-based audio diagnostic tools designed for speed and clarity. With no downloads or sign-u
LaunchChair
LaunchChair transforms your ideas into a working MVP by auto-generating specs and dynamic prompts, streamlining your AI product development.
Headless Domains
Headless Domains empowers AI agents with secure, verifiable identities, ensuring trust and seamless interactions across platforms.